I had my quasi-weekly call with Dustin Lang (Perimeter) today, in which we discussed how to represent the differences between images, or represent models of images. I am obsessing about how to model distortions of spectrograph calibration images (like arcs and flats), and Lang and I endlessly discuss difference imaging to discover time-variable phenomena and moving objects. One thing Lang has observed is that sometimes a parametric model of a reference image makes a better reference image for image differencing than the reference image itself. Presumably this is because the model de-noises the data? But if so, could we just use a band-limited non-parametric model say? We discussed many things related to all that.
Showing posts with label point-spread function. Show all posts
Showing posts with label point-spread function. Show all posts
2021-07-22
2020-12-04
group meeting awesome; color light curves from CoRoT
Today at the Astronomical Data Group meeting (led by Dan Foreman-Mackey) we did our quasi-monthly thing of getting a quick update from everyone who shows up. And 18 people showed up! Everyone gave an update; it was great to see the breadth of activity in the group. One contribution that got me excited was Christina Hedges (Ames, but still part of the Group!), who is looking at ESA CoRoT data. The mission was designed to have some tiny bit of color sensitivity, which makes it possible to look at colored light-curve variations and distinguish causal effects. This builds on work by Hedges to look at tiny point-spread-function changes in NASA Kepler and TESS data to get a tiny bit of color information in those white-light missions. Colored light curves are the future.
2018-06-19
#wetton18, day 1
Today was the first day of the Wetton Workshop at Oxford. There were many interesting talks from all over the map, but with a goal at understanding how we make sure that we stay open to unexpected discoveries, even as we make more and more targeted data sets and experiments. One theme that emerged is that of systematics: As you push data harder and harder&mdashin cosmology or exoplanet search or anything else—you become more and more sensitive to the details of your hardware and electronics and selection and so on. This led to a discussion of end-to-end simulation of data sets to understand how hardware issues enter and to see if we understand the hadware.
That's important! But I think there is an equally important aspect to this: If we don't take our data with sufficient heterogeneity, we can't learn certain things. For example, if you take all LSST exposures at 15 seconds, you never test the shutter, never test linearity of the detector, never find out on what time scales the PSF is changing, and so on. For another, if you take all the Euclid imaging survey on a regular grid, you never get cross-calibration information from one part of the detector to another, nor can you find certain kinds of anisotropies in the detector or the point-spread function. If we are going to saturate the bounds, we are going to need to take science data in many, many configurations.
Here are the slides from the public talk I gave at the end of the day. Note my digs at press-release artists' conceptions. I think we should be honest about what we do and don't know!
2018-06-06
#GaiaSprint, day 3
Boris Leistedt (NYU) and I have been talking for a while about a set of subjects related to the point that proper motions and parallaxes are both inversely related to distance, so you can use them to inform one another. This is a covariance induced by the geometry! Today he got this all working, along with a hierarchical inference of the velocity distribution in the Milky-Way halo. It is early days, but it looks like he substantially improves the parallax estimates for most stars. And, importantly, he can produce improved parallax likelihoods not just improved parallax posteriors. That is, they have wider use in downstream inference than, say, the Bailer-Jones et al distances. But still they will be hard to use absolutely correctly.
Andy Casey (Monash) and I discussed a possible a non-parametric model for the radial-velocity scatter delivered in Gaia DR2. This model would compare any star to its neighbors in relevant parameters (like color and apparent magnitude and housekeeping flags) to establish whether it has enough of a RV excess to be considered a likely binary.
Ana Bonaca (Harvard) showed me maps of the Jhelum stellar stream which make it look (to my eye) like a fold caustic! Many moons ago, Scott Tremaine (IAS) asked me if we could find various kinds of catastrophes in the stellar density, and I (and friends) responded with this paper on the cusp catastrophe. Maybe Bonaca has found one, but a fold! (And folds should be more common than cusps.)
Christina Eilers (MPIA) and I temporarily paused our methodological developments on our spectroscopic-parallax project and made maps of the Milky-Way disk. We tried plotting velocities, abundances, and vertical distortions (warps). Getting good visualizations is hard because the APOGEE selection function is so featured. That reminds me of why I am such a big fan of SDSS-V!
Many interesting things were shown in the afternoon check-in, but incredibly Sihao Cheng (JHU) and Sergey Koposov (CMU) found that galaxies appear in the Gaia DR2 data as variable stars! Why? Because the asymmetric Gaia point-spread function projects onto the complex galaxy morphology differently at different s/c orientations. That rocks! In principle the galaxy morphologies could be inferred from the time-variable data...
2017-11-09
mixture of factor analyzers; centroiding stars
On this, day four of my Hunstead Lectures, Andy Casey (Monash) came into town, which was absolutely great. We talked about many things, including the mixture-of-factor-analyzers model, which is a good and under-used model in astrophysics. I think (if I remember correctly) that it can be generalized to heteroskedastic and missing data too. We also talked about using machine learning to interpolate models, and future projects with The Cannon.
At lunch I sat with Peter Tuthill (Sydney) and Kieran Larkin (Sydney) who are working on a project design that would permit measurement of the separation between two (nearby) stars to better than one millionth of a pixel. It's a great project; the designs they are thinking about involve making a very large, but very finely featured point-spread function, so that hundreds or thousands of pixels are importantly involved in the positional measurements. We discussed various directions of optimization.
My talk today was about The Cannon and the relationships between methods that are thought of as “machine learning” and the kinds of data analyses that I think will win in the long run.
2017-05-25
what is math? interpolation of imaging
The research highlight of the day was a long call with Dustin Lang (Toronto) to discuss about interpolation, centroiding, and (crazily) lexicographic ordering. The latter is part of a project I want to do to understand how to search in a controlled way for useful statistics or informative anomalies in cosmological data. He found it amusing that my request of mathematicians for a lexicographic ordering of statistical operations was met with the reaction “that's not math, that's philosophy”.
On centroiding and interpolation: It looks like Lang is finding (perhaps not surprisingly) that standard interpolators (the much-used approximations to sinc-interpolation) in astronomy very slightly distort the point-spread function in imaging, and that distortion is a function of sub-pixel shift. He is working on making better interpolators, but both he and I are concerned about reinventing wheels. Some of the things he is worried about will affect spectroscopy as well as imaging, and, since EPRV projects are trying to do things at the 1/1000 pixel level, it might really, really matter.
2017-04-18
Dr Vakili
The research highlight of the day was a beautiful PhD defense by my student MJ Vakili (NYU). Vakili presented two big projects from his thesis: In one, he has developed fast mock-catalog software for understanding cosmic variance in large-scale structure surveys. In the other, he has built and run an inference method to learn the pixel-convolved point-spread function in a space-based imaging device.
In both cases, he has good evidence that his methods are the best in the world. (We intend to write up the latter in the Summer.) Vakili's thesis is amazingly broad, going from pixel-level image processing work that will serve weak-lensing and other precise imaging tasks, all the way up to new methods for using computational simulations to perform principled inferences with cosmological data sets. He was granted a PhD at the end of an excellent defense and a lively set of arguments in the seminar room and in committee. Thank you, MJ, for a great body of work, and a great contribution to my scientific life.
2017-02-13
JWST opportunity
Benjaming Pope (Oxford) arrived in New York today for a few days of visit, to discuss projects of mutual interest, with the hope of starting collaborations that will continue in his (upcoming) postdoc years. One thing we discussed was the JWST Early Release Science proposal call. The idea is to ask for observations that would be immediately scientifically valuable, but also create good archival opportunities for other researchers, and also help the JWST community figure out what are the best ways to make best use of the spacecraft in its (necessarily) limited lifetime. I am kicking around four ideas, one of which is about photometric redshifts, one of which is about precise time-domain photometry, one of which is about exoplanet transit spectroscopy, and one of which is about crowded-field photometry. The challenge we face is: Although there is tons of time to write a proposal, letters of intent are required in just a few weeks!
2016-06-10
likelihood functions for imaging
Mario Juric (UW) showed up for the day and we spoke for hours about many things. One category was image likelihood functions (for things like The Tractor or weak lensing). We came up with a very dumb (read: good!) idea for testing out ideas around likelihood functions: Take two image data sets from different telescopes that overlap on the sky. Build a catalog of sources (with positions and colors and so on) from a joint analysis of both data sets. Then do the same, but in a world in which your only interface to each data set is a callable API to a likelihood function! That is, something that takes as input a parameterized high-resolution image model and returns a likelihood value, given what it knows about its data and calibration, PSF, and so on. This would force us to figure out what would be needed in such an API. I think we would learn a lot, and it would help us think about how to construct next-next-generation data products. We also talked about image differencing, Dun Wang's Causal Pixel Model, and other matters of mutual interest.
2015-12-10
Gaia, validation, and K2
First thing in the morning, Andy Casey and I discussed some ideas for immediately following the first Gaia data release, which may be expanding in scope, apparently. We had the idea of gathering multi-band point-source photometry for as much of the sky as possible, and then using the data release to learn the relationship between the photometry and absolute magnitude. Then we can deliver all distances for every single point source we can! With error analysis. There would be a lot of users for such a thing.
By the end of the day, Casey had the validation working to set the regularization hyperparameter at each wavelength of the compressed-sensing version of The Cannon. Everything is looking as we predicted, so we will try to reproduce all of the results from the original Cannon paper, but now with a model with more sensible model freedom. I am extremely optimistic about where this project is going.
Mid-day I had a phone call to talk about photometry in K2 Campaign 9, which is in the bulge (and hence crowded). We discussed forward modeling and more data-driven detrending methods. But most importantly, we decided (more or less; final decision tomorrow) to do a tiny, half-pixel offset (dither) at the mid-campaign break. That might not sound like much, but I think it will significantly improve the calibration we can do and substantially increase the number of things we can learn.
2015-10-27
sampling in hard problems
In the morning, I had a call with Foreman-Mackey. We talked about various things. One is the possibility that we could fully sample the galaxy-deprojection or cryo-EM problems. My optimism comes from the fact that there are many samplings of low-level latent parameters that can be done independently at fixed high-level parameters. My pessimism comes from the fact that there are so many parameters. Foreman-Mackey was optimistic. We also talked about building a physical model for the Kepler focal plane (PSF, flat-field, and so on) for K2 data. We were a bit pessimistic about our options here, but we are contractually obliged to deliver something. We discussed ways we might combined data-driven and physics-driven approaches.
In the afternoon, Tarmo Aijo (SCDA) and the Rich Bonneau (SCDA) group talked with Greengard and me about their model for the time evolution of the human (gut) biome. They are using a set of Gaussian processes, manipulated into multinomials, to model the relative abundances of various components. It is an extremely sophisticated model, fully sampled by STAN, apparently. They asked us about speeding things up; we opined that it is unlikely (at the scale of their data) that the Gaussian processes are dominating the compute time.
2015-06-24
radical self-calibration
At group meeting, Fadely showed us plots that show that he can do what I call “radical” self-calibration with realistic (simulated) data from fields of stars. This is the kind of calibration where we figure out the flat-field and PSF simultaneously by insisting that the images we have could have been generated by point sources convolved with some pixel-convolved PSF. He also showed how the results degrade as our knowledge of the PSF gets wrong. We can withstand percent-ish problems with our PSF model, but we can't withstand tens-of-percent. That's interesting, and useful. I feel like we are pretty safe for our HST WFC3 calibration project though: We know the PSF very well and have a great first guess at the flat too.
At the same meeting, we bitched about the Astronomers' Telegram, looked at an outburst from a black-hole source, argued about mapping the sky with Fermi GBM, and looked at K2 data on a Sanchis-Ojeida planet. Oh and right after group meeting, Malz demonstrated to me conclusively that our Bayesian hierarchical inference of the redshift distribution—given probabilistic photometric redshifts—will work!
2015-06-19
K2 proposals
Today was #K2proposalSprint day. At group meeting, MJ gave us a review of a new paper on probabilistic approaches to weak lensing, which made many harsh (but useful) approximations. Then we pitched our K2 proposals and started writing. Price-Whelan pitched a proposal to find extragalactic exoplanets! One of the K2 fields touches the Sagittarius stream and therefor will contain (at Kepler sensitivity) some good red giants that might be planet hosts delivered by an accreted galaxy!. Fed Bianco pitched a proposal to do lucky imaging (and improve lucky-imaging pipelines) to follow up microlensing events in the K2 Campaign 9 field (which is a bulge-imaging project aimed at microlensing). I pitched a proposal to determine the PSF and flat-field in Campaign 9, where the field will be so crowded that, for one, the flat-field and PSF will be infer-able in the data, and, for another, the two things will need to be known at good precision to do any useful data analysis. We then spent the day working, but I have to admit I didn't get very far!
2015-06-12
radical self-calibration
At group meeting, Fadely showed us evidence that the radical self-calibration that we are executing for the HST WFC3 instrument can work: He showed that if you know the PSF—but nothing about any individual exposure—you can indeed infer the flat-field to some precision. Also and related, Vakili showed that he is getting pretty good estimates of the PSF in real HST WFC3 imaging. So we are getting close to going end-to-end on this project. I call this self-calibration “radical” because it doesn't rely on stars being observed more than once; it only relies on stable enough (or dense enough) imaging that the PSF can be accurately inferred. It works by asking what flat-field is required in order to generate good predictions for the data. One thing we are hoping: The quality of the results might depend more on the center of the PSF (the easy part) than the outskirts (the hard part); we are trying to understand that now. The long-term goal of this project is to save the asses of projects that took their data in violation of the principles for self-calibration.
2015-05-08
JPL, day 3
I spent the morning with Leonidas Moustakas (JPL), a bit of Foreman-Mackey (in Pasadena for the Sagan Fellowship Symposium), and a bit of Andrew Romero-Wolf (JPL) and Curtis McCully (LCOGT) by phone, discussing projects related to strong-lensing time-delay measurements. We discussed two challenging projects. The first is to determine (from as many as we can construct) the best model for quasar time-domain variability. There are claims in the literature that the damped random walk is the best model, but that (very sensible) model hasn't really been competed against all that much. We know how to do this, lets do this! The reason they want good probabilistic generative models is that they want to determine time delays as precisely as possible, using a probabilistic approach.
The second project is to perform high-quality photometry on the (overlapping from the ground) images of a strongly lensed quasar. In this case—when the point-spread functions overlap—you have to do your photometry by simultaneous fitting, but with the variable (and badly known) PSF of ground-based astronomy, I have never seen such photometry that really looks right: There are always fitting-induced covariances of the overlapping-source light curves. I think this is caused by model mismatch (under-fitting), but I don't really know. Romero-Wolf and McCully pointed out that image differencing methods work well in crowded fields, so I formulated an image-modeling approach to the photometry that is as close to image differencing as possible. I promised to write it up into a document. I am kind-of excited about it; it is still just image modeling, but it makes use of the power of image differencing technologies to get flexibility to fit the real PSF as it is.
Late in the day, Adam Miller (JPL) showed me the JPL Mission Control center and a few high bays, filled with awesome stuff (including some fake Mars!).
2015-04-24
self-calibration of GALEX, regularizing a PSF model
At group meeting, Dun Wang showed his first results from his work on the GALEX photons. He showed some example data from a scan across the Galactic plane and back, performed by Schiminovich in the spacecraft's last days. The naively built image has a double point-spread function, because the satellite attitude file is not quite right. Wang then showed that on second (or even half-second) time scales, he can infer the pointing, either by cross-correlating images, or else correlating with known stars. So the satellite pointing could be very well calibrated with a data-driven model. That's awesome!
Also at group meeting, Vakili discussed taking his model of the point-spread function up to super-resolution (that is, modeling the PSF at a resolution higher than the imaging data with which we constrain it). The model is super-degenerate, so we are in the process of adding (willy nilly) lots of different regularizations. My "big idea" at the meeting was to model the PSF using only smooth functions, because we know (for very deep physical reasons) that the PSF cannot have features or structure below some fundamental angular scale (set by the diameter of the telescope aperture!).
2015-04-20
vary all the exposure times!
[OMG I have been behind on posting. I will catch up this weekend (I hope).]
I have been batting around for years the idea of writing a paper about varying the exposure times in a survey. Typically, I have been thinking about such variation to test the shutter, look for systematics (like non-linearity) in the devices, extend dynamic range (that is, vary the brightness at which saturation happens) , and benefit from the lucky-imaging-like variation in the point-spread function. For all these reasons, I think the LSST project would be crazy to proceed with its (current) plan of doing 15+15 sec exposures in each pointing.
Recently, in conversations with Angus and Foreman-Mackey, I got interested in the asteroseismology angle on this: Could we do much better on asteroseismology by varying exposure times? I came up with a Cramér–Rao-bound formalism for thinking about this and started to code it up. It looks like a survey with (slightly) randomized exposure times vastly outperforms a survey with uniform exposure times on many fronts. Here's a plot from the first stab at this:
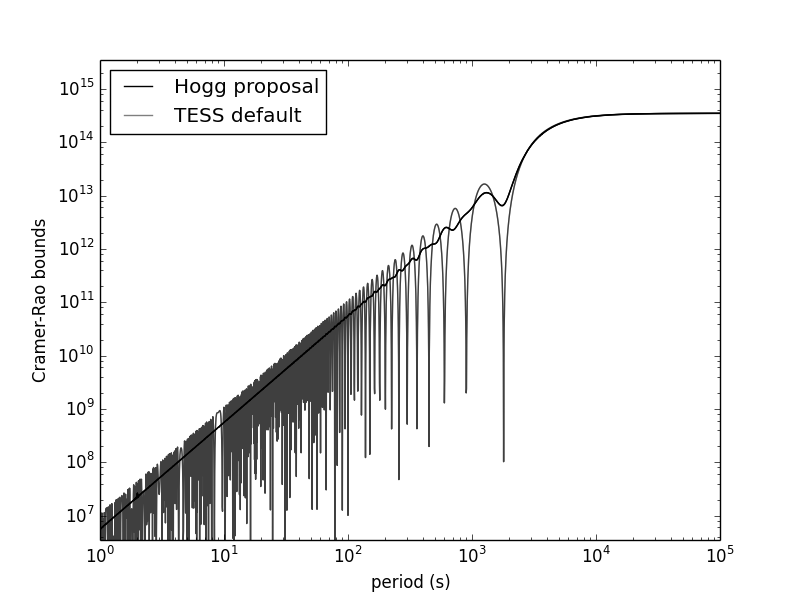
2015-01-23
finding exoplanets that aren't transiting
Avi Shporer (JPL) gave a nice talk this morning about finding planets in the Kepler data that are not transiting, using what's called "phase curves". There are multiple effects that make this possible: One is that close (hot) planets are heated asymmetrically, so they add to the lightcurve in a non-trivial way through the orbit. Another is relativistic beaming (seriously!) and another is produced by the ellipticity induced in the star tidally by the planet. Shporer has done a search of the Kepler data for such signals. He hasn't found many, but what he has found are all interesting. I got interested during the talk in the induced-ellipticity effect; this might have odd phase relations if the star is spinning.
In group meeting, we talked about various things, including Huppenkothen's Fermi proposal, Vakili's point-spread function model, and my proposals for cosmological inference using likelihood-free methods. I had lunch with Andrew Zirm (greenhouse.io) who used to work on galaxy evolution and is now a data scientist here in New York City. In the afternoon, Malz and I figured out the absolute simplest possible first project for doing hierarchical inference with probabilistic photometric redshifts.
2014-12-15
improving photometry hierarchically
Fadely handed me a draft manuscript which I expected to be about star–galaxy classification but ended up being about all the photometric measurements ever! He proposes that we can improve the photometry of an individual object in some band using all the observations we have about all other objects (and the object itself but in different bands). This would all be very model-dependent, but he proposes that we build a flexible model of the underlying distribution with hierarchical Bayes. We spent time today discussing what the underlying assumptions of such a project would be. He already has some impressive results that suggest that hierarchical inference is worth some huge amount of observing time: That is, the signal-to-noise ratios or precisions of individual object measurements rise when the photometry is improved by hierarchical modeling. Awesome!
Fadely and I also discussed with Vakili and Foreman-Mackey Vakili's project of inferring the spatially varying point-spread function in large survey data sets. He wants to do the inference by shifting the model and not shifting (interpolating or smoothing) the data. That's noble; we wrote the equations on the board. It looks a tiny bit daunting, but there are many precedents in the machine-learning literature (things like convolutional dictionary methods).
2014-11-19
ExoLab-CampHogg hack day
John Johnson (Harvard) came to NYU today along with a big fraction of his group: Ben Montet, Ruth Angus, Andrew Vanderburg, Yutong Shan. In addition, Fabienne Bastien (PSU), Ian Czekala (Harvard), Boris Leistedt (UCL), and Tim Morton (Princeton) showed up. We pitched early in the day, in the NYU CDS Studio Space, and then hacked all day. Projects included: Doing the occurrence rate stuff we do for planets but for eclipsing binaries, generalizing the Bastien "flicker" method for getting surface gravities for K2 data, building a focal-plane model for K2 to improve lightcurve extraction, documenting and build-testing code, modeling stellar variability using a mixture of Gaussians in Fourier space, and more! Great progress was made, especially on K2 flicker and focal-plane modeling. I very much hope this is the start of a beautiful relationship between our groups.
I also had long conversations with Leistedt about near-future probabilistic approaches to cosmology using our new technologies, Sanderson about series expansions of potentials for Milky Way modeling, Huppenkothen about AstroHackWeek 2015, and Vakili about star centroiding. In somewhat related news, during the morning pitch session, I couldn't stop myself from describing the relationships I see between structured signals, correlation functions, power spectra, Gaussian processes, cosmology, and stellar asteroseismology. I think we might be able to make asteroseismology more productive with smaller data sets.
Subscribe to:
Posts (Atom)